Dark Mode

NLTK Tense Form Detector Dataset
Education & Learning Analytics
Tags and Keywords
Trusted By



"No reviews yet"
Free
About
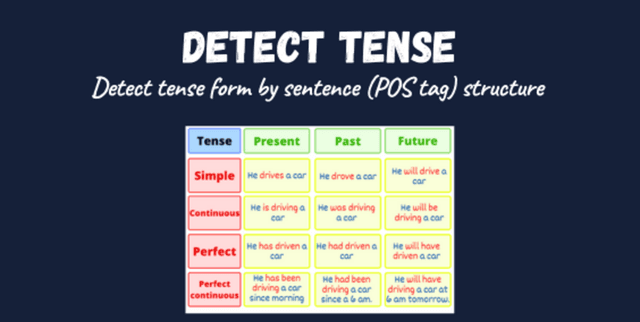
This dataset provides a collection of unique sentence structures, identified by their Part of Speech (POS) tags, and their corresponding English tense forms. It is designed to assist in determining the tense of a given sentence by matching its POS tag sequence. The structures included in the dataset have been generated using the
nltk.tag.pos_tag method [1]. This resource is invaluable for tasks requiring linguistic analysis and natural language processing [1].Columns
The dataset is primarily composed of two key columns, reflecting the structure and the associated tense form [1, 2]:
- pos_structure: This column contains sequences of Part of Speech tags, representing distinct sentence structures (e.g.,
DT,NN,NN,IN,DT,NN) [2]. - tense_form: This column specifies the English tense form that corresponds to the given POS tag structure (e.g.,
PRESENT_SIMPLE) [2].
Distribution
The dataset is provided in a CSV file format, named
pos_tag_wise_tense_form_rules.csv [1]. Specific numbers for rows or records are not available in the provided information.Usage
This dataset is ideally suited for applications that involve the detection of tense forms within sentences [1]. Key use cases include:
- Developing and training Natural Language Processing (NLP) models for linguistic analysis [1].
- Enhancing text processing pipelines to accurately identify sentence tenses [1].
- Educational tools for language learning and grammar analysis.
- Building rule-based systems for automatic tense recognition [1].
Coverage
The dataset's coverage is global, as indicated by its intended region of availability [3]. There is no specific time range associated with the linguistic data itself, as it pertains to general English grammar structures. No specific demographic scope is applicable to this dataset [3, 4].
License
CC0
Who Can Use It
This dataset is particularly useful for:
- Data Scientists and Machine Learning Engineers: For building and refining models that classify sentence tenses.
- Linguists and Computational Linguists: For research and analysis of English sentence structures and tenses.
- Educators and Students: As a learning resource for understanding POS tagging and tense identification [1].
- Developers: For integrating tense detection capabilities into various applications, such as grammar checkers or content analysis tools.
Dataset Name Suggestions
- POS Tag Tense Rules
- Sentence Tense Structure Data
- NLTK Tense Form Detector Dataset
- Grammar Tense Classification Data
Attributes
Original Data Source: POS Tag Dataset for Tense Form Detection.
Loading...