Dark Mode

Urdu Phonetic Alphabet Dataset
Knowledge Bundles
Tags and Keywords
Trusted By



"No reviews yet"
Free
About
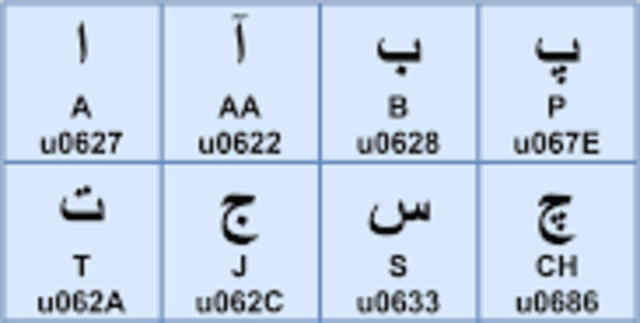
This dataset provides a collection of Urdu alphabets, each translated into its most commonly used and phonetically matched Roman Urdu counterpart. It serves as a valuable resource for natural language processing and linguistic studies involving the Urdu language.
Columns
- urdu: Represents the Urdu alphabets.
- roman: Provides the Roman Urdu phonetic translation for the corresponding Urdu alphabet.
Distribution
The dataset is typically provided in a CSV file format. The 'urdu' column contains 41 unique values. While the exact number of rows or records is not specified, an illustrative distribution of characters within the 'urdu' column shows 'a' and 'za' each making up 7%, with the remaining 35 unique characters accounting for 85% of the entries.
Usage
This dataset is ideal for developing natural language processing (NLP) applications, creating language learning tools, and for academic research in linguistics, particularly focusing on Urdu and Roman Urdu transliteration.
Coverage
The dataset has a global coverage, making it suitable for international applications. Specific time ranges or demographic scopes are not detailed.
License
CC0
Who Can Use It
Intended users include NLP developers building translation or transliteration systems, linguists and researchers studying phonetic variations, educators creating language learning materials for Urdu, and data scientists interested in multilingual text processing.
Dataset Name Suggestions
- Urdu Roman Transliteration Data
- Urdu Phonetic Alphabet Dataset
- Romanised Urdu Characters
- Urdu Script to Roman Mapping
Attributes
Original Data Source: Urdu_to_Roman_Urdu_Alphabets
Loading...