Dark Mode

Global Central Bank Communication Data
Data Science and Analytics
Tags and Keywords
Trusted By



"No reviews yet"
Free
About
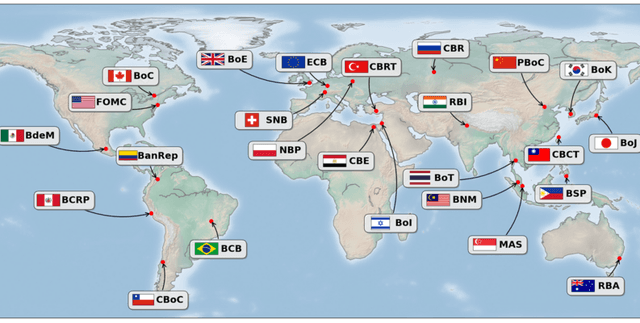
This dataset features 25,000 annotated sentences extracted from official central bank documents worldwide. Its primary purpose is to facilitate the analysis and deciphering of global central bank communications. Each sentence is categorised across three distinct tasks: Stance Detection, Temporal Classification, and Uncertainty Estimation, making it a valuable resource for understanding monetary policy sentiment and future outlook.
Columns
- sentence: The text extracted directly from official central bank documents.
- stance_label: Indicates the monetary policy stance, labelled as:
- hawkish: Supporting a contractionary monetary policy.
- dovish: Supporting an expansionary monetary policy.
- neutral: Containing neither hawkish nor dovish sentiment, or a mix of both.
- irrelevant: Not pertaining to monetary policy discussions.
- time_label: Specifies the temporal nature of the sentence:
- forward-looking: Discusses future economic events or policy decisions.
- not forward-looking: Discusses past or current economic events or decisions.
- certainty_label: Assesses the level of certainty conveyed:
- certain: Information presented definitively.
- uncertain: Information presented with speculation, possibility, or doubt.
- year: The publication year of the original document from which the sentence was taken.
- central_bank: The central bank that issued the document, drawn from a total of 25 different banks.
Distribution
The dataset is provided as a CSV file and contains 25,000 unique annotated sentences.
The distribution of key labels is as follows:
- Stance Labels: neutral (35%), dovish (33%), and other categories (32%).
- Temporal Labels: not forward-looking (56%) and forward-looking (44%).
- Uncertainty Labels: certain (77%) and uncertain (23%).
Usage
This dataset is ideally suited for applications in:
- Natural Language Processing (NLP), including sentiment analysis and text classification.
- Machine Learning (ML) model training for financial text understanding.
- Data Science and Analytics projects focused on economic forecasting and policy impact.
- Academic research into central banking and monetary policy communication.
Coverage
The dataset spans documents published from 1996 to 2024. It includes sentences originating from 25 different central banks, providing a global perspective on monetary policy communications.
License
CC-BY-NC-SA
Who Can Use It
- Data Scientists and Machine Learning Engineers for developing and testing NLP models.
- Economists and Financial Analysts seeking to analyse central bank statements and monetary policy trends.
- Academic Researchers in fields such as economics, finance, and computer science.
- Policymakers interested in understanding the communication strategies of global central banks.
Dataset Name Suggestions
- Global Central Bank Communication Data
- Monetary Policy Stance and Outlook Dataset
- Annotated Central Bank Statements
- Central Bank Text Analysis Corpus
- WCB Annotated Sentences
Attributes
Original Data Source: WCB Dataset (Annotated)
Loading...