Dark Mode

DinoDS Lane 05: Conversation Mode.
LLM Fine-Tuning Data
Tags and Keywords
"No reviews yet"
Free
About
About
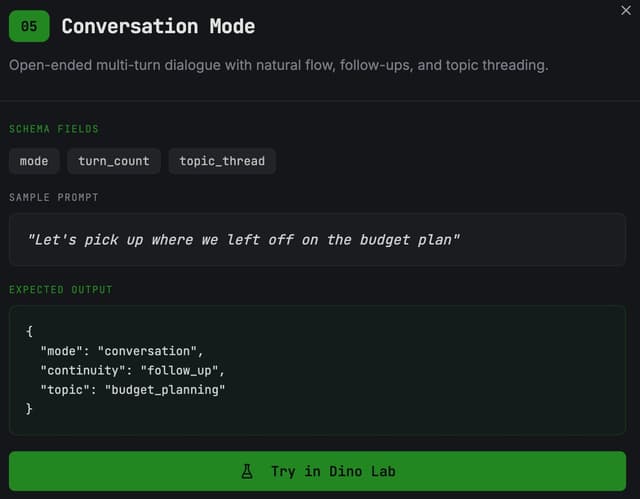
Dino Data Conversation Mode Preview is a focused assistant-training dataset built from Lane 05: Conversation Mode.
It is designed for multi-turn conversational behavior, where the model must:
- maintain context across turns
- keep tone consistent
- repair tone when needed
- ask for clarification
- move the interaction toward a concrete next step
This dataset is useful for conversational assistants, support copilots, messaging workflows, and companion-style agents where continuity matters.
Data Product Features
This dataset is provided as structured CSV files with row-level metadata for filtering, training, and evaluation.
Included columns
sample_id: Unique identifier for each rowsplit: Dataset split (train,validation,test)language: Language of the examplemode: Response modetone: Desired response toneintent_family: Broad task categoryintent_subtype: More specific task subtyperepresentation_choice: Preferred output stylecontinuity_choice: Continuity handling labelflow_state: Interaction flow labelhistory_scope: Scope of contextual historysafety_tag: Safety classificationneeds_search: Whether external search is requiredneeds_history_search: Whether history retrieval is requiredconnector_needed: Whether workflow/connector behavior is impliedhas_tool_call: Whether a tool/action structure is presenttool_name: Tool name when applicablemessage_count: Number of messages in the conversation sequenceis_multi_turn: Whether the example is multi-turnuser_message: User-side inputassistant_response: Target assistant response
Distribution
- Format: CSV
- Language: English
- Lane source:
lane_05_conversation_mode - Total rows: 100
- Number of columns: 21
Split structure
train.csv: 90 rowsvalidation.csv: 5 rowstest.csv: 5 rowsall_rows.csv: 100 combined rows
Usage
This data product is useful for:
- Conversational fine-tuning: Train models to handle ongoing threads instead of isolated prompts
- Tone and continuity control: Improve how assistants maintain tone while staying actionable
- Reply drafting systems: Support better follow-up and check-in message generation
- Support and service workflows: Improve multi-turn communication where clarification and next-step guidance matter
- Evaluation and filtering: Use metadata to select subsets by tone, intent, and conversation structure
Business Case and Value
Many models can generate fluent replies, but they often lose context, repeat themselves, or fail to move a conversation forward.
This dataset addresses that gap by focusing on thread-aware, tone-controlled, multi-turn response behavior. It is especially valuable for products where conversation quality directly affects user trust, clarity, and task completion.
Listing Stats
VIEWS
30
DELIVERY
INSTANT DOWNLOAD
LISTED
21/04/2026
UPDATED
28/05/2026
REGION
GLOBAL
![]() QUALITY
QUALITY
5 / 5
Loading...
Free
Download Dataset in CSV Format
Recommended Datasets
Loading recommendations...