Dark Mode

Romanised Urdu Stopword Dataset
Knowledge Bundles
Tags and Keywords
Trusted By



"No reviews yet"
Free
About
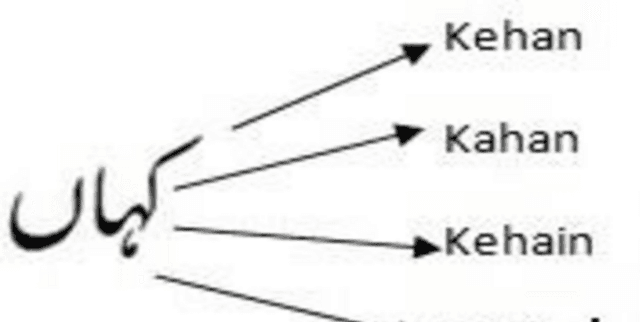
This dataset contains a collection of the most common Urdu stop words, which have been translated into Roman Urdu using phonetic alphabets. Each Roman Urdu version represents the most commonly used form of that particular stop word. It serves as a valuable resource for natural language processing tasks and linguistic analysis, helping to preprocess text by filtering out high-frequency, low-information words.
Columns
- urdu: Represents the original Urdu word.
- roman: Contains the phonetic Roman Urdu translation of the corresponding Urdu word.
Distribution
The dataset is typically provided in a CSV file format. It comprises 324 unique stop words, with each row representing a distinct Urdu stop word and its Roman Urdu translation. Specific numerical details on total rows/records beyond the unique count are not available.
Usage
This dataset is ideal for various applications, including:
- Natural Language Processing (NLP): For text cleaning, tokenisation, and pre-processing steps in NLP pipelines.
- Information Retrieval: Improving search accuracy by removing noise words.
- Machine Learning: Enhancing the performance of text-based machine learning models by reducing dimensionality.
- Linguistic Research: Studying the commonality and phonetic representation of Urdu stop words.
- Sentiment Analysis: Filtering out common words that do not contribute significantly to sentiment.
Coverage
The dataset has a global applicability, as Urdu stop words are universally relevant for Urdu language processing tasks. No specific geographic, time range, or demographic scope limitations are noted for the data's availability or relevance.
License
CC0 License
Who Can Use It
This dataset is suitable for:
- Data Scientists: For building and refining NLP models.
- NLP Engineers: For developing and deploying text processing systems.
- Linguists and Researchers: For academic studies on the Urdu language and its phonetic representations.
- Developers: For integrating Urdu text analysis capabilities into applications.
- Content Creators: For optimising Urdu content by understanding common word usage.
Dataset Name Suggestions
- Urdu Roman Stop Words
- Phonetic Urdu Stopwords
- Urdu NLP Stopword List
- Romanised Urdu Stopword Dataset
- Urdu Stopword Collection
Attribute
Original Data Source: urdu-to-roman-urdu-stop-words
Loading...