Dark Mode

Synthetic PII Annotation Corpus
Synthetic Data Generation
Tags and Keywords
Trusted By



"No reviews yet"
Free
About
This dataset is specifically designed for PII (Personally Identifiable Information) data detection, created as an external resource for The Learning Agency Lab. It was generated using GPT to provide a rich source of data for identifying sensitive information within text. Its primary purpose is to facilitate the development and testing of algorithms aimed at protecting privacy by accurately detecting and categorising various types of PII.
Columns
- Essay: This column contains the textual data where PII may be embedded. It features 2000 unique text entries, all of which are valid.
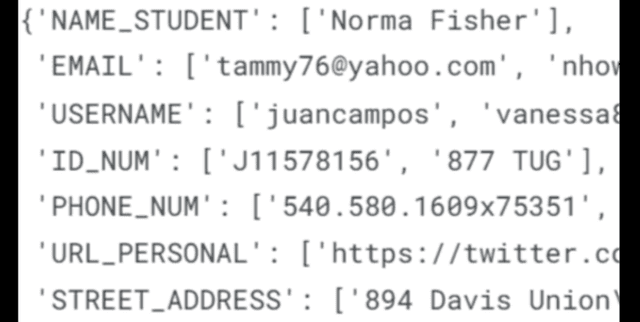
- PII: This column holds the detected PII information for each corresponding 'Essay' entry. The data is structured to detail specific PII types such as student names, email addresses, usernames, identification numbers, phone numbers, and personal URLs. Like the 'Essay' column, it also contains 2000 unique entries and is entirely valid.
Distribution
The dataset is provided in a CSV (Comma Separated Values) format and is approximately 6.31 MB in size. It comprises two distinct columns and is structured across 2000 rows or records, with each record containing an essay and its associated PII detections.
Usage
This dataset is ideal for:
- Developing and training machine learning models for automated PII detection.
- Testing the effectiveness and accuracy of existing privacy protection algorithms.
- Research and academic studies focused on natural language processing and data privacy.
- Building applications that require sensitive information identification and anonymisation.
Coverage
The dataset's content is synthetically generated using GPT, focusing on common PII types found in various textual contexts. Specific geographic, time range, or demographic scope is not explicitly defined, as the data is created to represent diverse PII patterns rather than real-world individual data.
License
Attribution 4.0 International (CC BY 4.0)
Who Can Use It
This dataset is particularly useful for:
- Data Scientists and Machine Learning Engineers: For building and refining PII detection models.
- Researchers and Academics: Engaging in studies related to privacy-preserving AI and NLP.
- Software Developers: Integrating PII detection capabilities into their applications.
- Educational Institutions: For teaching and demonstrating concepts of data privacy and security.
Dataset Name Suggestions
- Learning Agency Lab PII Detection Dataset
- GPT-Generated PII Identification Data
- Synthetic PII Annotation Corpus
- Privacy Information Extraction Data
Attributes
Original Data Source: Synthetic PII Annotation Corpus
Loading...