Dark Mode

Synthetic Stroke Prediction Dataset
Patient Health Records & Digital Health
Tags and Keywords
Trusted By




"No reviews yet"
£179.99
About
This synthetic Stroke Prediction Dataset is designed for educational and research purposes in the fields of data science, public health, and stroke research. It contains essential demographic, health, and lifestyle indicators such as age, hypertension, heart disease, and smoking habits, which can be used to analyze and predict the risk of stroke. The dataset is ideal for building predictive models, conducting risk assessments, and exploring the relationships between lifestyle factors and stroke risk.
Dataset Features
- Gender: The biological sex of the individual (Male/Female).
- Age: The age of the individual in years.
- Hypertension: Whether the individual has hypertension (Yes/No).
- Heart Disease: Whether the individual has heart disease (Yes/No).
- Ever Married: Marital status of the individual (Yes/No).
- Work Type: Type of work the individual is engaged in (Self-employed, Private, Government, Children, etc.).
- Residence Type: Type of residence (Urban/Rural).
- Average Glucose Level: The individual’s average glucose level (float, measured in mg/dL).
- BMI: Body Mass Index of the individual (float).
- Smoking Status: Smoking habits of the individual (Smokes, Formerly Smoked, Never Smoked, Unknown).
- Stroke: Binary classification indicating stroke risk:
- YES: At risk of stroke.
- NO: Not at risk of stroke.
Distribution
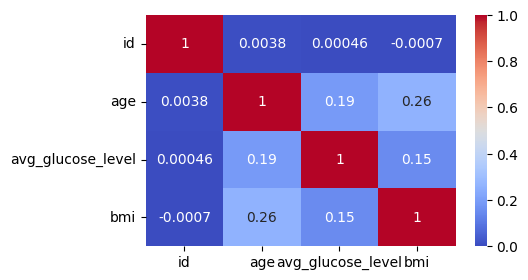
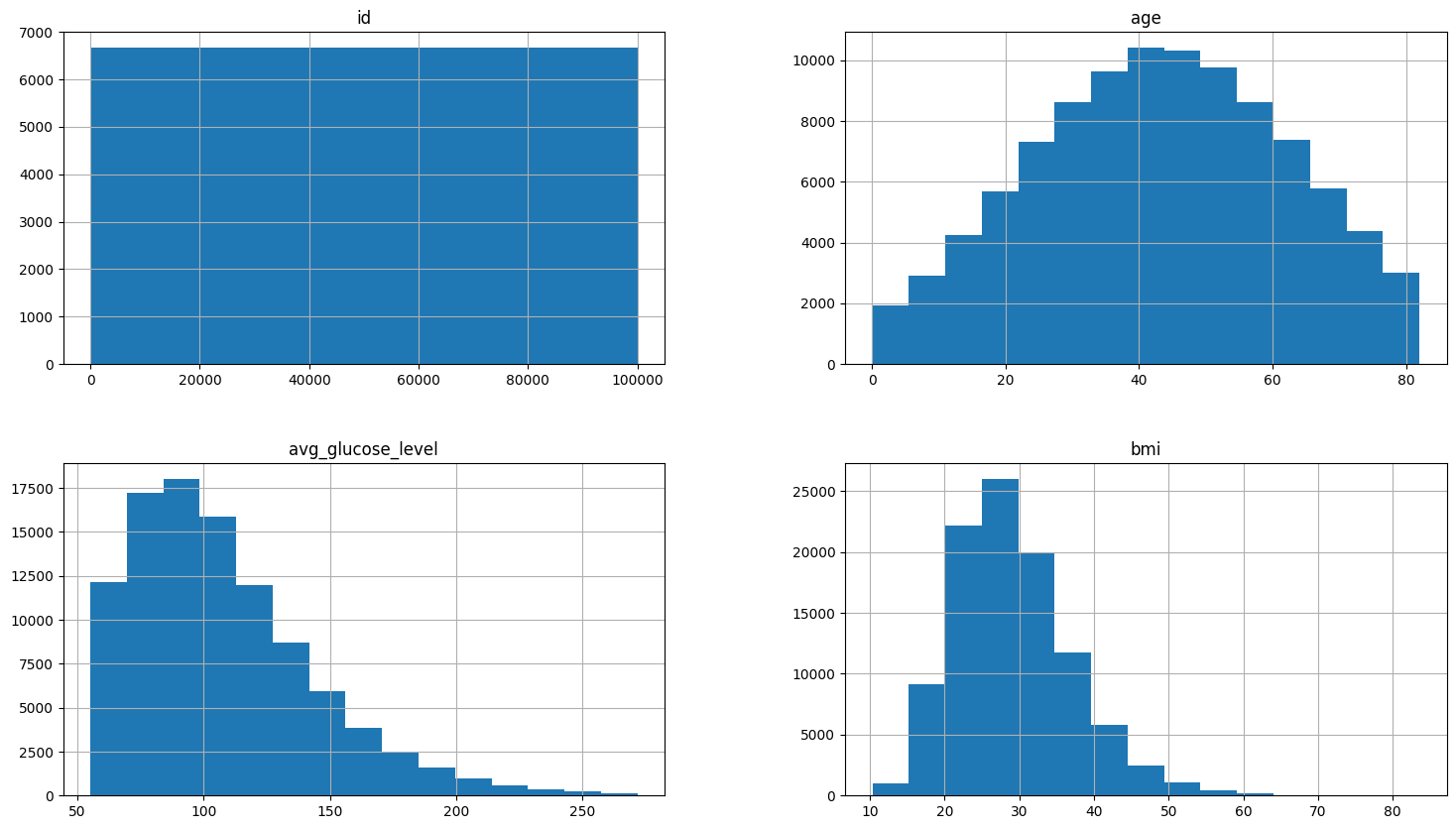
Usage
This dataset is ideal for various stroke-related applications:
- Stroke Risk Prediction: Develop machine learning models to classify individuals as at risk or not at risk of stroke.
- Risk Factor Analysis: Identify key factors contributing to stroke risks and prioritize interventions.
- Predictive Modeling: Build predictive models using demographic and health indicators to assess stroke risk.
- Public Health Research: Study the relationships between health metrics, lifestyle factors, and stroke risks.
- Preventive Healthcare: Inform public health campaigns and individual preventive measures to reduce stroke risks.
Coverage
This synthetic dataset is anonymized, ensuring compliance with data privacy standards. It is designed for research and learning purposes, providing diverse health conditions and demographic data for analysis and model building.
License
CC0 (Public Domain)
Who Can Use It
- Data Science Practitioners: For practicing data preprocessing, classification, and regression tasks related to stroke risk.
- Healthcare Professionals and Researchers: To explore relationships between health metrics and stroke risks.
- Public Health Analysts: To understand trends and develop interventions for reducing stroke risks.
- Policy Makers and Regulators: For data-driven decision-making in preventive healthcare policies.
Loading...