Dark Mode

Automated Loan Approval Dataset
Finance & Banking Analytics
Tags and Keywords
Trusted By



"No reviews yet"
Free
About
This dataset is designed to help a finance company automate their home loan eligibility process. It contains various customer details provided during online application forms, such as gender, marital status, education, number of dependents, income, loan amount, and credit history [1]. The primary purpose is to enable the identification of customer segments eligible for loan amounts, allowing the company to target these customers effectively and streamline real-time loan validation [1].
Columns
- Loan_ID: A unique identifier for each loan application [2].
- Gender: Indicates the applicant's gender, with Male (78%) and Female (19%) as common values [2].
- Married: A boolean field showing the applicant's marital status, with True (63%) and False (37%) [2].
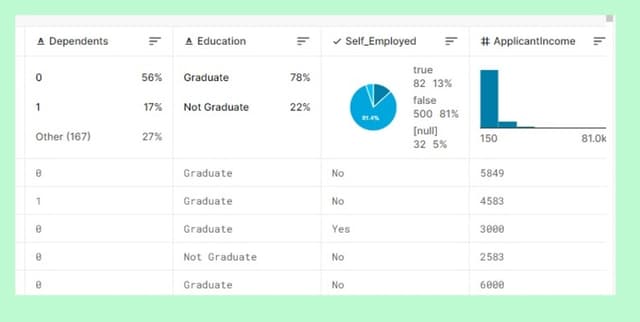
- Dependents: The number of dependents the applicant has, with 0 dependents (54%) being the most common [2].
- Education: The applicant's education level, predominantly Graduate (77%) [2].
- Self_Employed: A boolean field indicating if the applicant is self-employed, with False (84%) being most common [3].
- ApplicantIncome: The income of the applicant, with a mean of 4.81k [3, 4].
- CoapplicantIncome: The income of any co-applicant, with a mean of 1.57k [4].
- LoanAmount: The amount of the loan requested in thousands, with a mean of 136 and most common values around 80.20-132.40 (160 entries) [4, 5].
- Loan_Amount_Term: The term of the loan in months, with 360 months (312 entries) being the most frequent [5].
- Credit_History: A numerical field indicating credit history, with a mean of 0.83 and 0.90-1.00 (279 entries) being common [6].
- Property_Area: The type of property area, with Urban (38%) and Semiurban (32%) as common categories [6].
Distribution
The dataset is provided in a CSV format [7, 8]. It contains 367 records (e.g., Loan_ID, Married, Education, ApplicantIncome, CoapplicantIncome, Property_Area have 367 valid entries) [2-4, 6]. The test file size is 21.96 kB [7]. Some columns have missing values, including Gender (3% missing), Dependents (3% missing), Self_Employed (6% missing), LoanAmount (1% missing), Loan_Amount_Term (2% missing), and Credit_History (8% missing) [2, 3, 5, 6].
Usage
This dataset is ideal for developing and evaluating machine learning classification algorithms [7]. It can be used for tasks such as:
- Building predictive models to automate home loan eligibility decisions [1].
- Identifying and characterising eligible customer segments for targeted marketing [1].
- Performing exploratory data analysis and data visualisation in the finance sector [7].
Coverage
The dataset includes demographic information such as gender, marital status, education, and number of dependents [1, 2]. Details regarding the geographic location or specific time range of the data are not specified within the provided sources.
License
CC0: Public Domain
Who Can Use It
- Finance companies aiming to automate and streamline their loan approval processes [1].
- Data analysts and data scientists working on predictive modelling and customer segmentation problems in banking or finance [7].
- Machine learning engineers interested in applying classification algorithms to real-world business challenges [7].
Dataset Name Suggestions
- Home Loan Eligibility Prediction Data
- Automated Loan Approval Dataset
- Customer Loan Eligibility Predictor
- Finance Loan Approval Prediction Data
Attributes
Original Data Source: Automated Loan Approval Dataset
Loading...
Free
Download Dataset in ZIP Format
Recommended Datasets
Loading recommendations...