Dark Mode

Diabetes Diagnostic Measurements
Patient Health Records & Digital Health
Tags and Keywords
Trusted By



"No reviews yet"
Free
About
This dataset is designed to diagnostically predict whether a patient has diabetes based on specific diagnostic measurements. The data originates from the National Institute of Diabetes and Digestive and Kidney Diseases. A key characteristic of this dataset is that all included patients are females, at least 21 years old, and of Pima Indian heritage. It comprises several independent medical predictor variables and one target dependent variable.
Columns
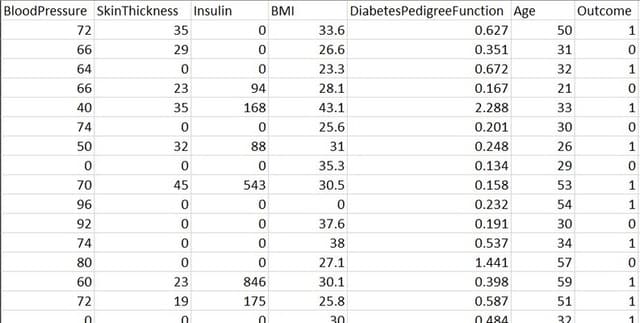
The dataset contains 9 columns, each providing a specific diagnostic measurement or outcome:
- Pregnancies: Represents the number of times pregnant.
- Glucose: Denotes the glucose level in blood.
- BloodPressure: Indicates the blood pressure measurement.
- SkinThickness: Expresses the thickness of the skin.
- Insulin: Represents the insulin level in blood.
- BMI: Refers to the Body Mass Index.
- DiabetesPedigreeFunction: Expresses the diabetes percentage, a function that scores the likelihood of diabetes based on family history.
- Age: States the age in years.
- Outcome: The final result, where '1' indicates the presence of diabetes and '0' indicates no diabetes. This is the target dependent variable.
Distribution
The dataset is provided in a CSV file format, specifically "diabetes.csv", with a file size of 23.88 kB. It contains 768 records, each with 9 variables. The structure includes several independent medical predictor variables and a single target dependent variable (Outcome).
Usage
This dataset is ideally suited for developing and evaluating machine learning models aimed at diagnostically predicting diabetes. It can be used for classification tasks, healthcare predictive analytics, and research into risk factors for diabetes within a specific demographic.
Coverage
The dataset focuses on a specific demographic: females who are at least 21 years old and of Pima Indian heritage. The geographic scope is implied by the origin of the Pima Indian population, typically the Southwestern United States. A specific time range for data collection is not detailed, but the dataset is expected to be updated annually.
License
CC0: Public Domain
Who Can Use It
This dataset is suitable for:
- Data scientists and machine learning engineers: For building and testing predictive models for diabetes.
- Medical researchers and epidemiologists: To study diabetes prevalence and risk factors in specific populations.
- Healthcare analysts: For insights into diagnostic measurements related to diabetes.
- Students: For educational purposes in data science, statistics, and health informatics.
Dataset Name Suggestions
- Pima Indian Diabetes Prediction Dataset
- Diabetes Diagnostic Measurements
- Pima Female Diabetes Data
- Healthcare Diabetes Predictive Analysis
Attributes
Original Data Source: Diabetes Diagnostic Measurements
Loading...
Free
Download Dataset in CSV Format
Recommended Datasets
Loading recommendations...