Dark Mode

Synthetic Healthcare Insurance Dataset
Healthcare Insurance & Costs
Tags and Keywords
Trusted By




"No reviews yet"
£79.99
About
This synthetic insurance dataset has been generated as an educational resource for data science, machine learning, and data analysis applications in the healthcare insurance domain. The data reflects real-world insurance records, focusing on individual demographic and health-related features, and is designed for users to practice data manipulation, develop analytical skills, and build predictive models related to healthcare costs and insurance trends.
Dataset Features:
- Age: Age of the individual (in years), an important demographic factor influencing insurance charges.
- Sex: Gender of the individual, categorized as “male” or “female.”
- BMI (Body Mass Index): A numerical value representing the individual’s body mass index, calculated from height and weight. BMI is an indicator of body fat and plays a key role in assessing health risks.
- Children: Number of dependents covered under the insurance plan.
- Smoker: Smoking status of the individual, categorized as “yes” or “no.” Smoking is a significant factor affecting insurance costs.
- Region: Residential region of the individual in the United States, categorized as “northeast,” “northwest,” “southeast,” or “southwest.”
- Charges: Medical insurance charges billed to the individual, expressed in USD. This serves as the target variable for predictive modelling.
Usage:
This dataset is useful for a variety of applications, including:
- Insurance Analytics: To explore trends and patterns in healthcare insurance, such as how demographic and lifestyle factors impact insurance charges.
- Educational Training: To teach data cleaning, transformation, and visualization techniques, with a focus on insurance and healthcare costs.
- Predictive Modeling: To develop models that predict insurance charges based on demographic, lifestyle, and health-related features.
- Healthcare Policy Research: To analyze how factors like smoking and BMI influence healthcare costs, informing policy decisions.
Distribution:
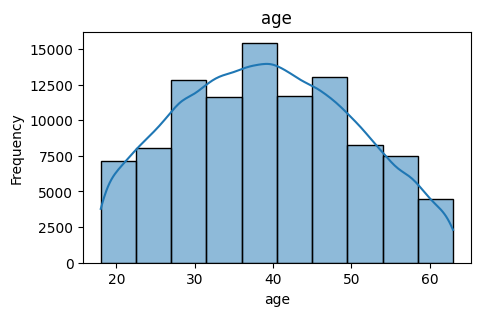
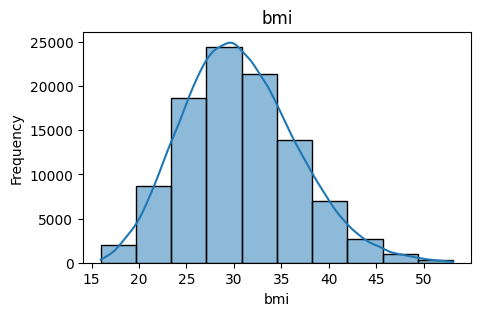
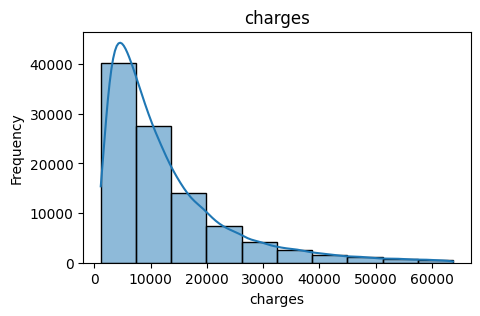
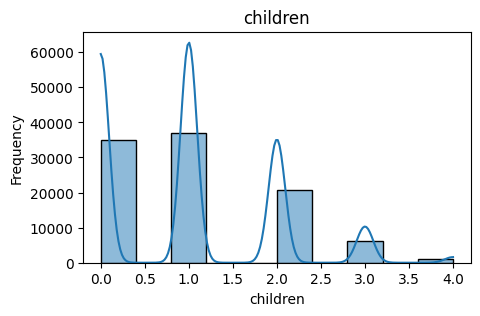
Coverage:
This dataset is synthetic and anonymized, making it a safe tool for experimentation and learning without compromising real-world data privacy.
License:
CC0 (Public Domain)
Who Can Use It:
- Researchers and Educators: For studies or teaching purposes in healthcare insurance analytics and data science.
- Data Science Enthusiasts: For learning, practising, and applying data manipulation and analysis techniques in the context of insurance data.
- Healthcare Professionals: For exploring and understanding the impact of demographic and health factors on insurance costs, improving cost prediction models.
Loading...
£79.99
Download Dataset in CSV Format
Recommended Datasets
Loading recommendations...